本文共 4666 字,大约阅读时间需要 15 分钟。
算法面试必备-----模型评估与选择
算法面试必备-----模型评估与选择
基本概念
方差与偏差
过拟合与欠拟合
场景描述
在模型评估与调整的过程中,我们往往会遇到“过拟合”或“欠拟合”的情况 。 如何有效地识别 “过拟台”和“欠拟合"现象 ,并有针对性地进行模型调整 ,是不断改进机器学习模型的关键。特别是在实际项目中,采用多种方法、从多个角度降低“过拟合”和“欠拟合”的风险是算法工程师应当真备的领域知识。知识点
过拟合、欠拟合
问题:在模型评估时,过拟合与欠拟合具体是什么现象?
分析与解答
过拟合是指模型对于训练数据拟合呈过当的情况, 反映到评估指标上 ,就是模型在训练集上的表现很好,但在测试集和新数据上的表现较差 。欠拟台娼的是模型在训练和预测时表现都不好的情况。
图 2.5 形象地描述了过拟台和欠拟台的区别 。
问题:能否说出几种降低过拟合与欠拟合风险的方法?
分析与解答


模型评估方法(测试集的保留方法)
留出法


交叉验证法



自助法

缺点:
改变初始数据集分布,会引入估计偏差问题:在自助法的采样过程中,对 n 个样本进行n次自助采样,当n趋于无穷大时,最终有多少数据从来被选择过?
分析与解答


调参与最终模型(验证集的使用)
为了调参,经常会加一个数据集----验证集
训练集训练,验证集看结果,调参,再看验证集结果
参数调完后,最后再测试集上看结果问题:在模型评估中,有哪些主要的评估方法,他们的优缺点是什么?



模型性能度量
任务描述

错误率与精度

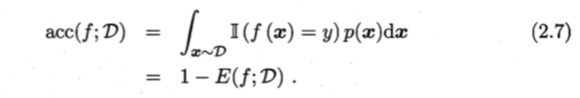
问题:准确率的局限性
Hulu的奢侈品广告主们希望把广告走向投放给奢侈品用户。 Hulu通过第三方的数据管理平台( Data Management Platform , DMP )拿到了一 部分奢侈晶用户的数据 ,并以此为训练集和测试集,训练和测试用户的分类模型。该模型的分类准确率超过了95%, 但在实际广告投放过程中, 该模型还是把大部分广告投给了非奢侈品用户,这可能是什么原因造成的?
分析与解答
在解答该问题之前,我们先回顾一下分类准确率的定义。准确率是指分类正确的样本占总样本个数的比例,即 准确率是分类问题中最简单也是最直观的评价指标,但存在明显的 缺陷 。比如,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得 99% 的准确率。所以,当不同类别的样本比例非常不均衡时, 占比大的类别往往成为影响准确率的最主要因素。
准确率是分类问题中最简单也是最直观的评价指标,但存在明显的 缺陷 。比如,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得 99% 的准确率。所以,当不同类别的样本比例非常不均衡时, 占比大的类别往往成为影响准确率的最主要因素。 显然,奢侈且用户只占 Hulu 全体用户的一小部分,虽然模型的整体分类准确率高 ,但是不代表对奢侈晶用户的分类准确率也很高。在线上投放过程中 ,我们只会对模型判定的“奢侈晶用户"进行投放,因此,对“奢侈品用户”判定的准确率不够高的问题就被放大了。为了解决这个问题,可以使用更为有效的平均准确率 (每个类别下的样本准确率的算术平均)作为模型评估的指标。
查准率(Precision)、查全率(Recall)



问题: 精确率与召回率的权衡
Hulu提供视频的模糊搜索功能,搜索排序模型返回的 Top 5 的精确率非常高,但在实际使用过程中,用户还是经常找不到想要的视频,特别是一些比较冷门的剧集,这可能是哪个环节出了问题呢?
分析与解答
要回答这个问题,首先要明确两个概念,精确率和召回率。精确率(查准率)
是指分类正确的正样本个数占分类器判定为正样本的样本个数的比例 。 召回率(查全率) 是指分类正确的正样本个数占真正的正样本个数的比例 。Precision 值和 Recall 值是既矛盾又统一的两个指标,为了提高Precision 值,分类器需要尽量在“更高把握”时才把样本预测为正样本,但此时往往会因为过于保守而漏掉很多“没有把握”的正样本,导致 Recall 值降低 。
回到问题中来,模型返回的 Precision@5 的结果非常好,也就是说排序模型 Top 5 的返回值的质量是很高的。但在实际应用过程中,用户为了找 一些冷门的视频,往往会寻找排在较靠后位置的结果,甚至翻页去查找目标视频。但根据题目描述,用户经常找不到想要的视频,这说明模型没有把相关的视频都找出来呈现给用户。 显然,问题出在召回率上。 如果相关结果有100 个,即使 Precision@5 达到了 100%, Recall@5 也仅仅是 5%。在模型评估时,我们是否应该同时关注 Precision值和 Recall值? 进一步而言,是否应该选取不同的 Top N 的结果进行观察呢?是否应该选取更高阶的评估指标来更全面地反映模型在 Precision 值和 Recall 值两方面的表现?
答案都是肯定的,为了综合评估一个排序模型的好坏,不仅要看模型在不同 Top N 下的 Precision@N 和 Recall@N,而且最好绘制出模型的 P-R (Precision-Recall )曲线。这里简单介绍一下 P-R 曲线的绘制方法。
P-R 由线的横轴是召回率,纵铀是精确率。
对于一个排序模型来说,其P-R 曲线上的一个点代表着,在某一阈值下 ,模型将大于该阈值的结果判定为正样本,小于该阈值的结果判定为负样本,此时返回结果对应的召回率和精确率 。 整条 P-R 由线是通过将阈值从高到低移动而生成的。 图 2.1 是 P-R 曲线样例图,其中实线代表模型 A 的 P-R 曲线,虚线代表模型B的 P-R曲线。原点附近代表当闺值最大时模型的精确率和召回率。

P-R曲线



混淆矩阵

F1值



ROC和AUC





问题:什么是ROC曲线?
分析与解答
ROC 曲线是 Receiver Operating Characteristic Curve 的简称 , 中文名为“受试者工作特征曲线” 。 ROC 曲线源于军事领域,而后在医学领域应用甚广, “受试者工作特征曲线 ” 这一名称也正是来自于医学领域 。


问题:如何绘制ROC曲线?
分析与解答




问题:如何计算AUC?
分析与解答

问题:ROC曲线相比于P-R有什么特点?
分析与解答
本章第二小节曾介绍过同样被经常用来评估分类和排序模型的 P-R 曲线。相比 P-R 曲线, ROC 曲线奇一个特点,当 正负样本的分布发生 变化时, ROC 曲线的形状能够基本保持不变,而 P-R 曲线的形状一般 会发生较剧烈的变化 。 举例来说 3 圄 2.3是 ROC 曲线和 P-R曲线的对比图 , 其中图 2.3( a)和国 2.3 ( c )是 ROC 曲线,圄 2.3 ( b )和国 2.3 ( d )是 P-R 由线,圄 2.3 ( c )和国 2.3 ( d )则是将测试集中的负样本数量增加 10信后的曲线圄。
可以看出, P-R 曲线发生了明显的变化,而 ROC 曲线形状基本不 变 。 这个特点让 ROC 曲线能够尽量降低不同测试集带来的干扰,更加客观地衡量模型本身的性能 。这有什么实际意义呢?在很多实际问题中 ,正负样本数量往往很不均衡 。 比如,计算广告领域经常涉及转化率模型,正样本的数量往往是负样本数量的 1/1000 甚至 1/10000。 若选择不同的测试集,P-R 曲线的变化就会非常大,而 ROC 曲线则能够更加稳定地反映模型本身的好坏。所以,ROC 曲线的适用场景更多,被广泛用于排序、推荐 、 广告 等领域。 但需要注意的是,选撵 P-R 曲线 还是 ROC 曲线是因实际问题而异的,如果研究者希望更多地看到模型在特定数据集上的表现,P-R曲线则能够更直观地反映真性能。
代价敏感错误率与代价曲线(多种训练集一种算法)







解释
1.明确参数 p = m+/m
2.代价去西安基本思路
目的:对于一个模型,根据p不同,找到使得代价总期望最小的模型的阈值横轴:归一化的正概率代价期望
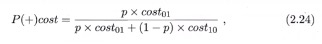
纵轴:归一化的总代价期望
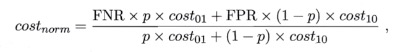
大致过程:
给定p,给定模型 根据归一化代价期望的最小值 确定圈1圈2圈3圈4的比例 阈值决定了这个比例 反过来说,这个比例确定了,阈值也就确定了 也就是模型固定下来了 同时模型的综合考量指标P,R,F1,Fbeta啥的都确定下来了聚类评估指标
外部度量(知道类簇label)
有监督的方法,需要基准数据。用一定的度量评判聚类结果与基准数据的符合程度。
ACC


Jaccard系数(Jaccard Coefficient, JC)
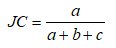
FM指数(Fowlkes and Mallows Index, FMI)
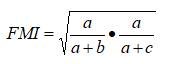
Rand指数(Rand Index, RI)
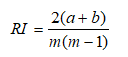
( a+b+c+d=m(m-1)/2 )
上述性能度量的结果值均在[0,1]区间,值越大越好。
内部度量(在真实的类簇label不知道的情况)
CH指标
 轮廓系数
轮廓系数 
深度聚类评估指标
模型参数调优
场景描述
对于很多算法工程师来说 ,超参数调优是件非常头疼的事。除了根据经验设定所谓的“合理值”之外,一般很难找到合理的方法去寻找超参数的最优取值。而与此同时,超参数对于模型效果的影响又至关重要。有没有一些可行的办法去进行超参数的调优呢?问题:超参数有哪些调优方法?
分析与解答
为了进行超参数调优,我们一般会采用网格搜索 、随机搜索、贝叶斯优化等算法。在具体介绍算法之前,需要明确超参数搜索算法一般包括聊几个要素。 一是目标函数,即算法需要最大化/最小化的目标 二是搜索范围,一般通过上限和下限来确定 三是算法的其他参数,如搜索步长 。网格搜索
网格搜索可能是最简单、应用最广泛的超参数搜索算法 , 它通过查 找搜索范围内的所有的点来确定最优值。 如果采用较大的搜索范围以及较小的步长,网恪搜索高很大概率找到全局最优值。 然而,这种搜索方案十分消耗计算资源和时间,特别是需要调优的超参数比较多的时候 。 因此,在实际应用中,网格搜索法一般会先使用较广的搜索范围和较大的步长,来寻找全局最优值可能的位置;然后会逐渐缩小搜索范围和步长,来寻找更精确的最优值。 这种操作方案可以降低所需的时间和计算量, 但由于目标函数一般是非凸的 ,所以很可能会错过全局最优值。随机搜索
随机搜索的思想与网恪搜索比较相似 ,只是不再测试上界和下界之间的所有值,而是在搜索范围中随机选取样本点。它的理论依据是,如果样本点集足够大,那么通过随机采样也能大概率地找到全局最优值,或其近似值。随机搜索一般会比网恪搜索要快一些,但是和网恪搜索的快速版一样,它的结果也是没法保证的。贝叶斯优化算法
贝叶斯优化算法在寻找最优最值参数时,采用了与网恪搜索、随机搜 索完全不同的方法。网恪搜索和随机搜索在测试一个新点时,会忽略前一 个点的信息,而贝叶斯优化算法则充分利用了之前的信息。 贝叶斯优化算法通过对目标函数形状进行学习,找到使目标函数向全局最优值提升的参数。具体来说,它学习目标函数形状的方法是,首先根据先验分布,假设 一个搜集函数,然后,每一次使用新的采样点来测试 目标函数时,利用这个信息来更新目标函数的先验分布;最后,算法测试由后验分布给出的全局最值最可能出现的位置的点。对于贝叶斯优化算法,一个需要注意的地方,一旦找到了一个局部最优值,它会在该区域不断采样,所以很容易陷入局部最优值。为了弥补这个缺陷,贝叶斯优化算法会在探索和利用之间找到一个平衡点, “探索”就是在还未取样的区域获取采样点;而“利用”则是根据后验分布在最可能出现全局最值的区域进行采样。转载地址:http://nluib.baihongyu.com/